
You ever wonder how Perplexity delivers those long, multi-layered research reports without crashing mid-way?
Most AI tools choke when you throw them a complex task. They spin for a few seconds, return some half-baked answer, and call it a day. But Perplexity? It runs deep research tasks that take MINUTES — not seconds — and somehow keeps you updated in real-time, step by step, without breaking a sweat.
Let's crack open the hood and see what's actually happening under there.
The WebSocket Trick: Why Perplexity Doesn't Just "Call an API"
Here's where it gets interesting.
Go to Perplexity right now. Fire up a deep research task. Then open your browser's Inspect Element → Network tab. Watch closely.
You'll see Perplexity doesn't just make a standard HTTP request and wait for a response. Nope. It opens a WebSocket connection — a live, two-way data stream between your browser and their server.
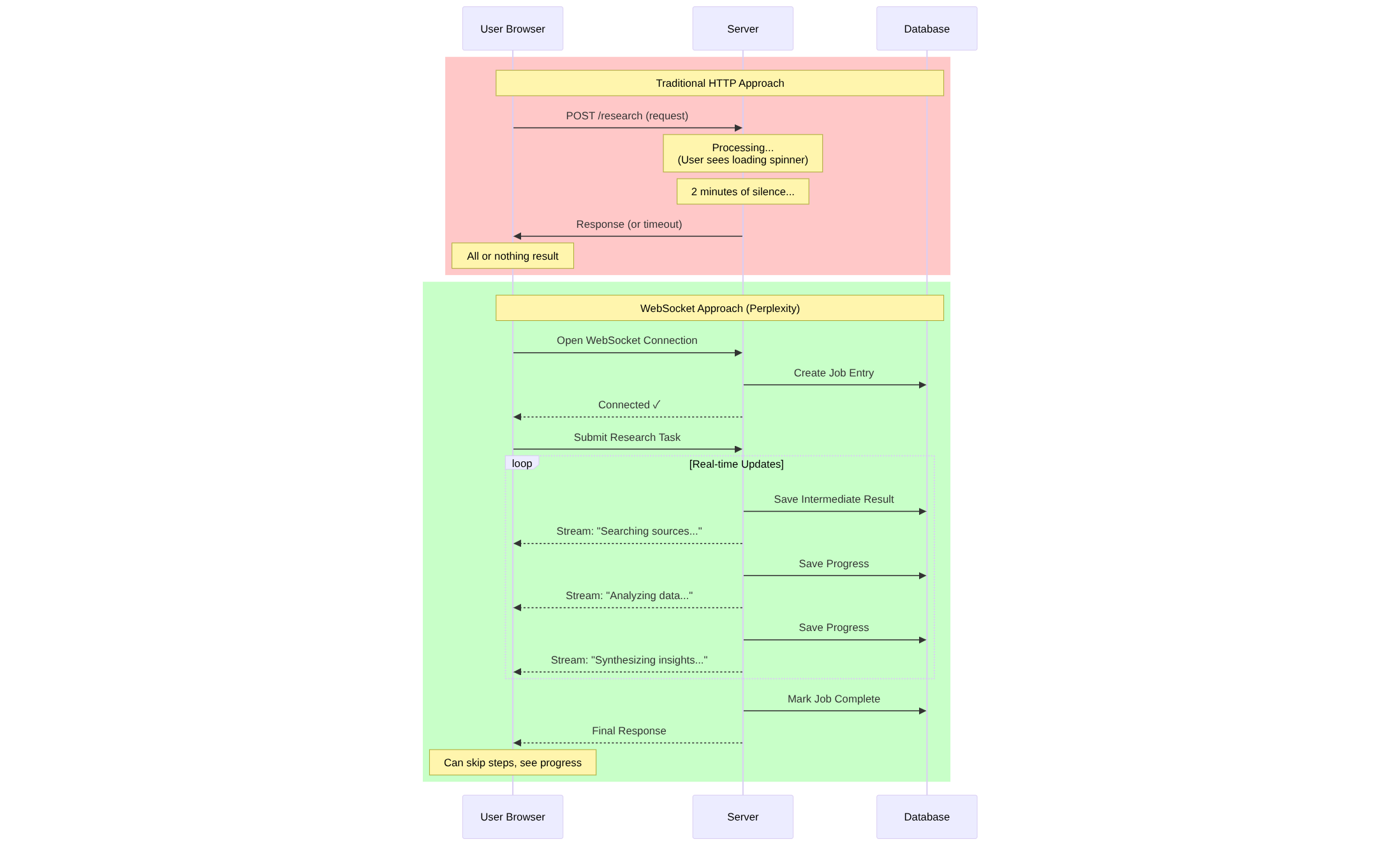
Why does that matter?
Because with a WebSocket, the server can push updates to you continuously, in real-time, as the research unfolds. You're not just waiting for a final answer. You're watching the AI think, query, analyze, synthesize — LIVE.
And here's the kicker: you can even intervene mid-task. Skip certain steps. Redirect the search. That's not possible with traditional REST APIs. This is event-driven architecture at its finest.
But Wait — What About Memory and State Management?
Now, you might be thinking: "Okay cool, WebSockets. But if this task takes 5 minutes and involves 20+ search queries, database lookups, and reasoning steps… is all of that happening in memory?"
If yes, that's a disaster waiting to happen.
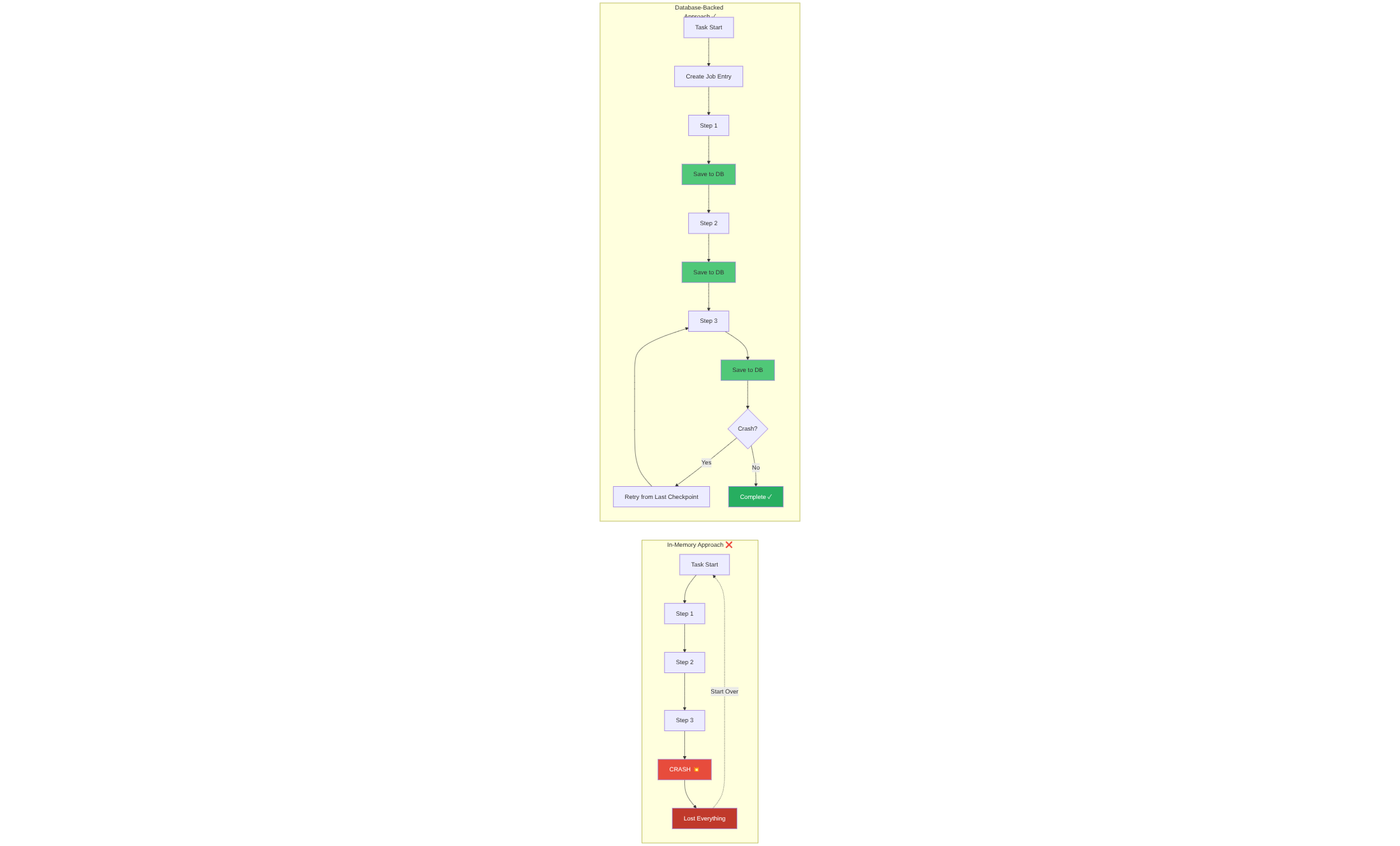
Imagine your research task is 80% done, the server hiccups, the process dies — and BOOM. You're back to square one. No retry. No recovery. Just frustration.
That's NOT how Perplexity does it.
The Smart Way: Database-Backed Job Management
Here's the real architecture move.
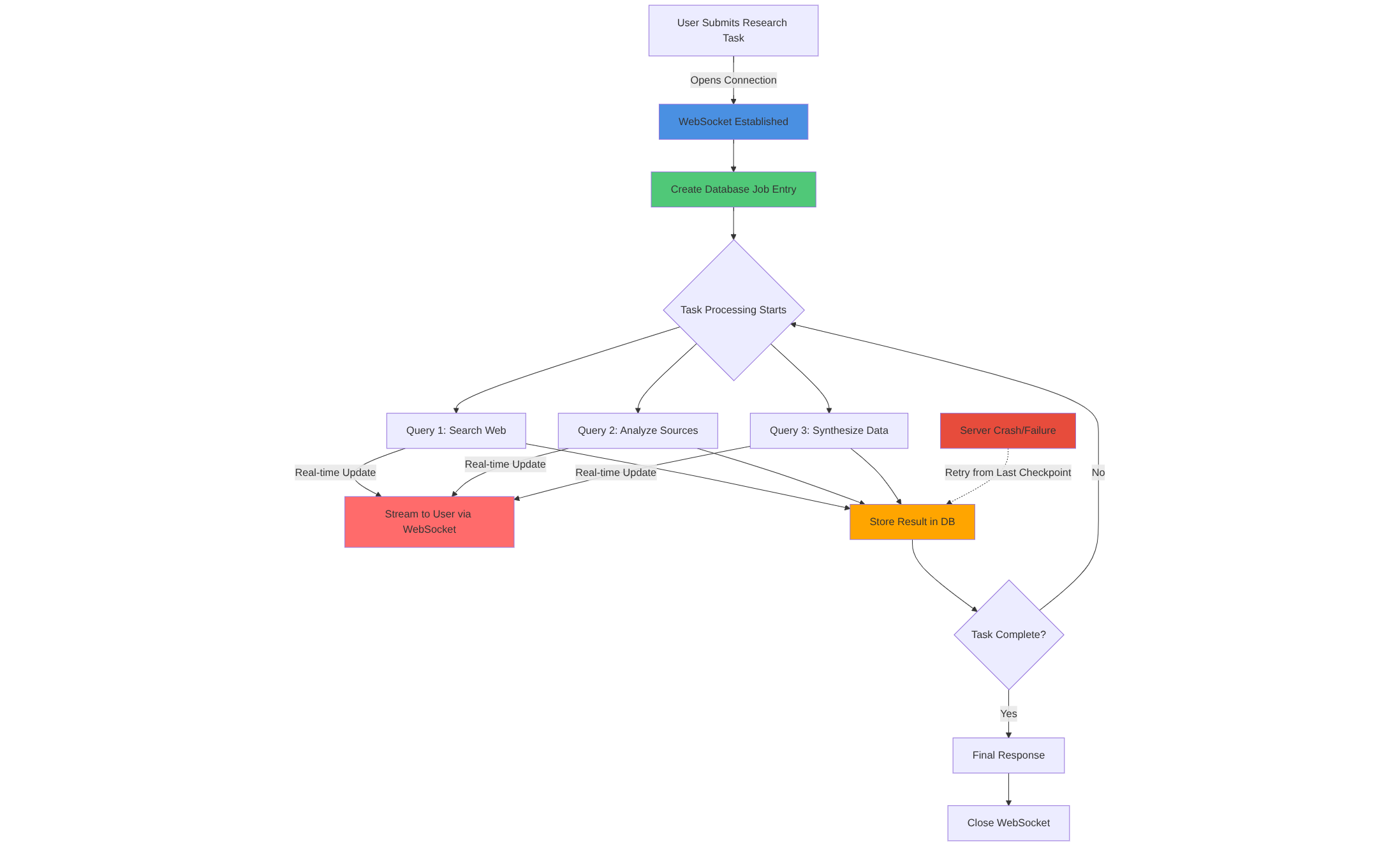
Every time you start a research task on Perplexity, the system creates a database entry for that job. Think of it like a work order that gets logged the moment you hit "Go."
Now, as the task runs:
- Every intermediate result gets stored in the database.
- Every search query, every insight generated, every step completed — logged.
- If something fails halfway? The system knows EXACTLY where it crashed. It can retry from that point, not from scratch.
This is called stateful job orchestration, and it's how production-grade AI systems handle long-running tasks without going insane.
Your screen shows you real-time updates via WebSocket. But behind the scenes? Everything's being written to persistent storage. The task is resilient. It's recoverable. It's fault-tolerant.
Why This Matters for Builders
If you're building an AI product that does anything more complex than "ask a question, get an answer," you NEED to think about this stuff.
Here's the reality check:
- In-memory task handling is fine for quick, stateless operations. Chatbots. Q&A. Simple stuff.
- But the moment you're dealing with multi-step workflows, long inference chains, or research-heavy tasks, you need durable state management.
Otherwise, you're asking users to gamble every time they click a button. Will it work? Will it crash? Will I lose 10 minutes of progress?
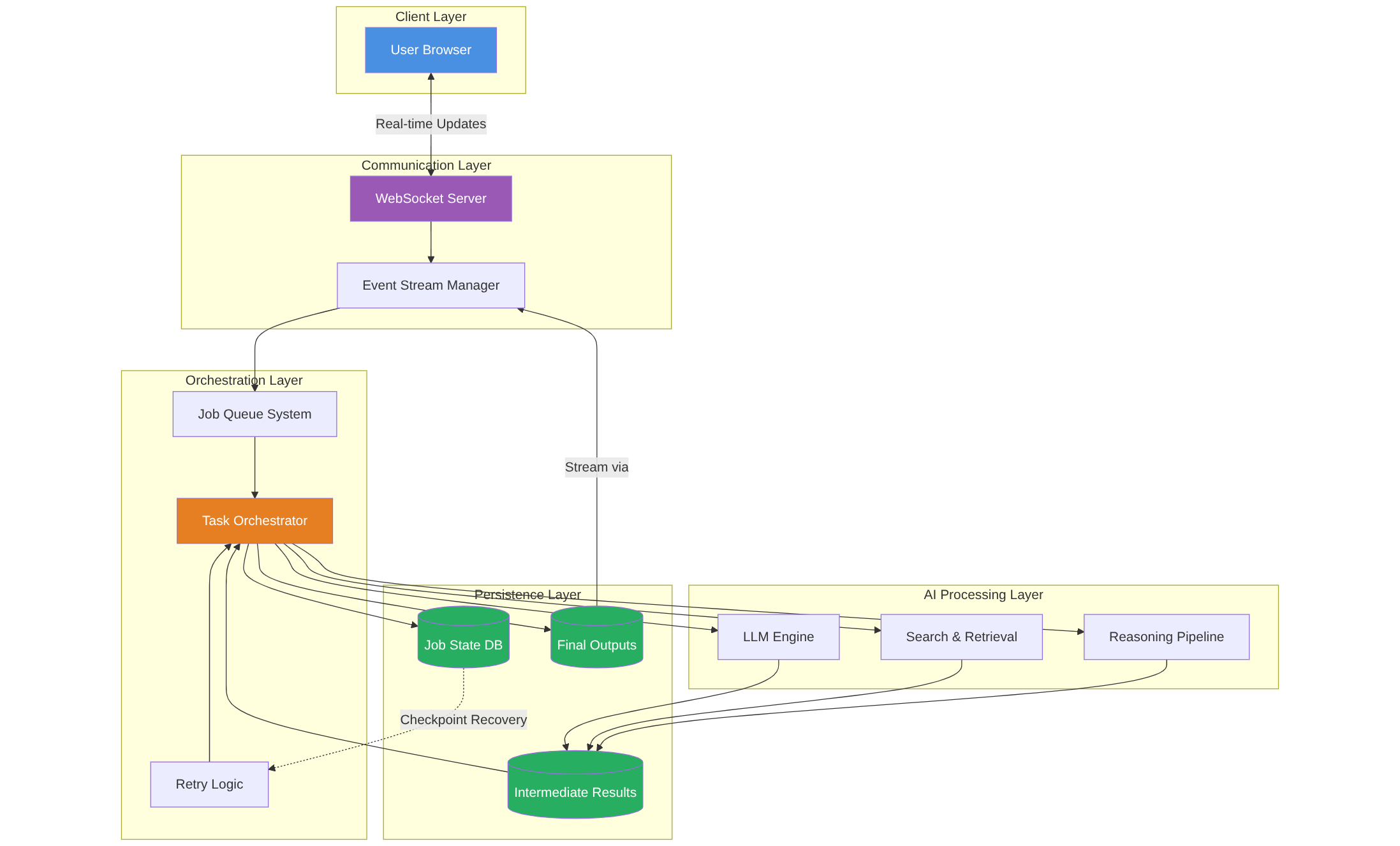
Perplexity solved this by treating every research task like a background job in a queue system. It's the same philosophy behind tools like Celery, RabbitMQ, or even modern serverless orchestrators like Temporal.
The AI engine does its thing. The WebSocket streams updates. The database stores state. And the user? They just see magic.
The Takeaway: Real-Time + Resilience = Production-Ready AI
This isn't just clever engineering. It's necessary engineering.
As AI moves from demos to products people actually depend on, we need systems that don't just run fast — they run reliably. That means:
- Event-driven communication (WebSockets, Server-Sent Events, etc.)
- Persistent job state (databases, not just memory)
- Graceful failure handling (retries, checkpoints, rollback logic)
Perplexity gets this. And if you're building anything in the AI space that involves complex, multi-step reasoning? You should get this too.
Because the future of AI isn't just about smarter models. It's about smarter infrastructure that makes those models actually usable at scale.
FAQ: Real Questions, Real Answers
How does Perplexity's Deep Research actually work under the hood?
Here's the thing most articles won't tell you: Perplexity's Deep Research performs dozens of searches, reads hundreds of sources, and reasons through material autonomously to deliver comprehensive reports in 2-4 minutes. But that's just what you SEE.
Behind the scenes? It's using WebSocket connections for real-time streaming, database-backed job management to track every step, and iterative reasoning loops that refine the research plan as it learns. Think of it like a human researcher — but instead of storing everything in their head (risky), it saves every intermediate result to a database. So if something crashes at minute 3? It picks up right where it left off. No data loss. No starting over.
That's production-grade AI architecture.
Why do AI tools use WebSockets instead of regular HTTP requests?
Because HTTP is like sending letters back and forth — you ask, you wait, server responds, connection closes. Repeat for every update. Painfully slow for real-time apps.
WebSockets enable real-time, bi-directional communication, making them ideal for applications that require constant data streaming and instant updates. Once the connection opens, both sides can send data ANYTIME. No overhead. No repeated handshakes. Just continuous, live updates.
That's why Perplexity can show you "Searching sources..." then "Analyzing data..." then "Synthesizing insights..." all in real-time. It's not magic. It's WebSockets doing what they do best: keeping you in the loop as the AI works.
What happens if a long AI research task crashes halfway through?
With bad architecture? You lose everything and start from scratch. Nightmare.
If an agent's runtime restarts due to a failure or version update, it should pick up right where it left off without losing crucial information or repeating the same tasks. That's why serious AI systems use database-backed state management.
Every search query, every result, every reasoning step gets logged to a database. If the server dies at step 15 of 20? The system reads the database, sees "Step 15 complete," and jumps straight to Step 16. You might not even notice the hiccup. That's resilience. That's how production systems work.
Is Perplexity faster than ChatGPT for research tasks?
Speed-wise? Yeah, usually.
Perplexity referenced 150% more sources than ChatGPT (50 vs. 20) and completed responses significantly faster. ChatGPT gives you deeper, longer reports (31 pages vs. 6 pages), but Perplexity optimizes for SPEED and SOURCE DENSITY.
If you need a quick, well-sourced answer in under 3 minutes? Perplexity. If you need a dissertation-length deep dive? ChatGPT. Different tools, different strengths. Pick based on what you actually need.
Why can't I just store AI task state in memory instead of a database?
Because memory is volatile. Server restarts? Gone. Process crash? Gone. User refreshes? Gone.
For applications needing long-term context, such as personalized workflows or multi-session tasks, persisted state is essential. In-memory is fine for quick, throwaway tasks. But for anything that takes MINUTES or involves multiple steps? You need durable storage.
Databases give you: recovery from failures, progress tracking, audit trails, and the ability to scale horizontally. Memory gives you... speed, until it doesn't. Choose wisely.
What's the difference between Pro Search and Deep Research on Perplexity?
Pro Search = enhanced single-query answers with better models and more sources. Fast. One-shot.
Deep Research performs dozens of searches automatically, reads hundreds of sources, reasons through material autonomously, and delivers comprehensive reports in 2-4 minutes. It's ITERATIVE. It searches, learns, adjusts its plan, searches again, synthesizes, and builds a full report.
Think of Pro Search as "ask a smart assistant." Deep Research is "hire a research analyst for 3 minutes." Totally different levels of depth.
Can I use WebSockets for any real-time app or just AI tools?
WebSockets work for ANY real-time use case: chat apps, live gaming, stock tickers, collaborative docs, IoT dashboards, sports scores, you name it.
WebSockets keep the connection open allowing for full-duplex, persistent communication between client and server, making them ideal for applications where constant data flow is needed.
But don't use them for everything. If you're just loading static data or making occasional API calls? Stick with HTTP. WebSockets have overhead — persistent connections consume server resources. Use them where real-time actually matters.
How do AI systems prevent users from losing progress during long tasks?
Two words: checkpointing and event sourcing.
Tools bring robust state management directly into code, letting you checkpoint agent state frequently so nothing is lost if things go sideways. Modern AI systems write every major step to persistent storage — databases, key-value stores, event logs.
If something fails, the orchestrator reads the last checkpoint, figures out what's incomplete, and resumes from there. You don't lose 10 minutes of compute. You don't annoy users. You just... continue. Like nothing happened.
Is Deep Research free on Perplexity?
Deep Research is free for all users with limited daily usage for non-subscribers, and unlimited access for Pro subscribers. Free users get about 5 queries per day. Pro users ($20/month)? 500 queries daily.
If you're doing serious research work or need unlimited access, Pro is worth it. For casual use? The free tier is surprisingly generous.
Why do modern AI apps need "durable runtimes"?
Because AI workflows aren't just one API call anymore. They're multi-step processes that can take MINUTES or even HOURS.
AI agents often run many inference calls, chain them with context, and produce iterative refinements — that means you need robust state management and recovery mechanisms.
Durable runtimes ensure that even if your container restarts, your VM dies, or your cluster rebalances — the AI agent remembers where it was and keeps going. Without that? Every failure means starting over. And at $200/month for OpenAI Pro? That's expensive.
Got more questions? Drop them in the comments. Or better yet — open up your browser's Network tab next time you use Perplexity and watch the WebSocket magic happen live. You'll never look at AI tools the same way again.





